
The new way to witness OCR: DeepSeek OCR

On October 20, 2025, DeepSeek released something that’s about to reshape how we handle documents in AI. It’s not another model it’s a complete rethink of Optical Character Recognition (OCR). DeepSeek has once again set the AI world buzzing with its new model, DeepSeek-OCR, they always comes and drop a banger and we wait to know what they are cooking from past few months.
Rather than simply improving OCR, it challenges fundamental assumption: LLMs must process information as long sequences of text tokens. DeepSeek-OCR shows that this doesn’t have to be the case, The new model can “see” information instead of just reading it, achieving the same understanding with a fraction of the computation.
In this blog we will cover :
Why Traditional OCR is a Waste?
How Traditional OCR Works?
What is this new thing ‘Contexts Optical Compression’?
How does DeepSeek-OCR work ?
How well does DeepSeek-OCR perform?
Why DeepSeek-OCR matters?
Why Traditional OCR is a Waste ?
Whether you are using Tesseract, GOT-OCR 2.0 or MinerU 2.0 they all have common flaw: they convert everything into endless sequences of text tokens.
When we feed a document into these models, every single word, space and punctuation marks become a token. A single paper that typically have 1,000 to 7,000+ tokens.
MinerU 2.0 averages 6,790 tokens per page
GOT-OCR 2.0 uses 256 tokens per page
With MinerU 2.0 processing 100 page document means dealing with 679,000 tokens, this matter because every token needs to pass through every layer of transformer.
More tokens means more floating point operations per second (FLOPs), more memory consumption, slower inference, and exponentially higher costs. It’s linear scaling at its worst and we are throwing compute at a problem that shouldn’t exist.
All LLM’s have a fixed upper limit a context window. Whether it’s 8k , 32k or even 128k tokens you can only process so much at once. The moment you exceed that limit, old information gets pushed out and forgotten.
Here’s something no one mentioned, not all tokens are useful headers, footers, whitespaces and markdown syntax your models burns compute cycles processing filler that adds zero understanding.
And when you encounter complex layout? Forget it. When everything gets flattened into 1D token sequence, spatial relationship disappears. All tables, graphs become meaningless sequence of words, the model has to reconstruct everything from scratch, and it fails constantly.
Organizations have tried the obvious solution make context window bigger, but here what happens- memory usage explodes quadratically with attention mechanisms. Inference latency skyrockets, your cloud bill goes through the roof. And despite that investment, performance still degrade after a certain length attention becomes diluted, accuracy drops.
How Traditional OCR works ?
Mostly I used Tesseract and MinerU so I will be vouching for them here, let’s see how they works:
Tesseract OCR -
the one grandfather of Open-Source OCR models, its architecture is straightforward:
Page layout analysis using morphological operations to find text blocks
Text detection with connected components analysis
Line and word segmentation
Character recognition using lstm networks with Connectionist temporal classification decoding.
but the problem: It’s ancient , It struggle with complex layouts, requires heavy preprocessing (binarization, noise reduction) and fails spectacularly on tables and multi columns documents. It’s still free and open source which is why many developers think of it and good for starting out.
MinerU 2.0 OCR -
It represent the current state of art (SOTA) with aggressive accuracy through sheer token budget:
Using 6,790 tokens per page average, it achieves high accuracy on complex tables and dense layouts because it’s throwing massive compute at the problem. But that approach is fundamentally unsustainable. Throughput is slow (2.12 pages/sec on A100-80 G), requires VRAM(80 GB) and costs multiply.
What is this new thing ‘Contexts Optical Compression’ ?
DeepSeek’s insight is elegant, stop treating text as tokens. Treat documents as visual data.
Traditional approach: Document → Text tokens → model
DeepSeek approach: Document → Image → Vision tokens → Models
Instead of converting text to endless token sequences, DeepSeek-OCR encodes entire sections of context as images, then compress those images into ultra compact vision tokens. The model “sees” the structure directly, preserving spatial relationships that text tokens destroy.
At 10x compression, you maintain 91.5% accuracy. Even at 20x compression, you are at 60% accuracy.
Comparing with traditional approaches :
MinerU 2.0- 6,790 tokens/page, no compression possible
GOT-OCR 2.0- 256 tokens/page
DeepSeek-OCR- 182 vision tokens/page, outperforms both
How does DeepSeek-OCR work ?
It features a unified end-to-end VLM architecture built around two brains that work together: a visual encoder and a language decoder.

Image Source: DeepSeek-OCR Research Paper
DeepEncoder
The DeepEncoder is where the compression happens. It handles high-resolution inputs more efficiently in terms of memory and token counts.
The DeepSeek team built it from the ground up because no existing open-source encoder met their requirements, they need a model that could:
process high resolutions efficiently
maintain low activation at high resolutions
create a small number of vision tokens
support multi-resolution inputs
keep a moderate parameter count
To keep these conditions the team designed a 380M parameters encoder that achieves high compression ratios and can output a manageable number of vision tokens, it combines three main components:
SAM-base(80M)- for visual perception using window attention, uses Segment Anything Model (SAM) for fine grained perception. This captures small details subscripts, diacritics, table borders, symbol. It uses windowed attention to see the detail without getting lost in big picture.
CLIP-large(300M)- provides holistic understanding with dense attention. This grasps overall document structure, layout and semantic meaning.
A 16x convolutional compressor- bridges the two, capable of reducing thousand of patch tokens into a few hundred vision tokens (example, 4096 patch tokens get compressed down to just 256 vision tokens), that’s extreme compression, and it works.
Multiple resolution support -
This is where DeepSeek get’s clever, DeepEncoder mainly support two major Input modes: Native resolution and Dynamic Resolution

Image Source: DeepSeek-OCR Research Paper
A simple slide-64 tokens, A dense newspaper- 800 tokens, it allocates compute where it matters, not blindly everywhere.
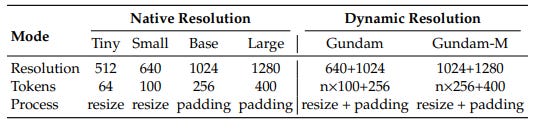
Image Source: DeepSeek-OCR Research Paper
DeepSeek-3B-MoE Decoder
Once the encoder compresses the input into visual tokens, the DeepSeek-3B-MoE Decoder turnd them back into text.
This decoder uses MoE design. During Inference, it activates only 6 of 64 experts plus 2 shared ones, totaling about 570M activated parameters. This gives it the power of a 3B model but the inference cost of one under 600M, and ideal balance between performance and efficiency.
The decoder receives the vision tokens and prompts, and generate the final output, including chemical structures and planar geometric figures.
The decoder is equally elegant:
3B parameters total
Mixture of Experts(MoE) architecture with only 570M active parameters per forward pass
Auxiliary-loss-free load balancing experts distribute work efficiently without adding overhead
8K max context length for the decoder
Here is why MoE is genius- only a subset of exports activate per token. It’s like having specialist you don’t call everyone for every task, just the right expert. This keeps compute low while maintaining quality.
How well does DeepSeek-OCR perform?
DeepSeek-OCR demonstrated strong efficiency and accuracy across benchmarks.
At a 10x compression ratio, it retains around 97% accuracy. Even at higher compression levels(up to 20x), it can still produce usable results at roughly 60% accuracy.

Image Source: DeepSeek-OCR Research Paper
On OmniBench, a leading benchmark for document understanding, DeepSeek-OCR outperforms established baselines such as GOT-OCR 2.0 and MinerU 2.0, achieving higher accuracy with far fewer tokens.

Image Source: DeepSeek-OCR Research Paper
The accuracy on tables is particularly impressive 0.163 vs GOT’s 0.459. That’s a 2.8x improvement on what’s historically been the hardest problem in OCR.
DeepSeek-OCR(Gundam) approaches MinerU 2.0 accuracy while using 756 token vs 6,790 token , that 8.5x fewer tokens for essentially the same quality.
Some result of its usage(mentioned in paper)

Figure 8:DeepSeek-OCR in deep parsing mode can also recognize chemical formulas within chemical documents and convert them to SMILES format. In the future, OCR 1.0+2.0 technology may play a significant role in the development of VLM/LLM in STEM fields.

Figure 9:DeepSeek-OCR also possesses the capability to copy (structure) simple planar geometric figures. Due to the intricate interdependencies among line segments in geometric shapes, parsing geometry task is extremely challenging and has a long way to go.
Why DeepSeek-OCR matters?
For Evaluation and Research
When traditional OCR loses structure, it’s catastrophic. Flattering tables and equations into text destroys alignment, borders, and spatial relationship. DeepSeek-OCR preservers visual layout which means:
Better table recognition: 2.8-5.2x improvement on tables
Formula accuracy: Complex multiline equation stay intact
Order preservation: Multi-column documents, footnotes, captions all handles correctly
For Long Context LLM Research
This is huge for AI memory research, in early stage of LLM, they have limited memory, when we used to ask gpt do you remember this project and sadly it response no , but now days with longer context and memory the long conversation is possible
Natural forgetting: Instead of hand dropping old token, DeepSeek can ‘downsample’ old context visually like human memory blurry over time.


Image Source: DeepSeek-OCR Research Paper
Historical compression: archive entire conversation or documents as visual streams then reconstruct later.
For Production Cost
Processing 1M Pages with MinerU 2.0 takes 6.79B tokens but DeepSeek do it in 182M tokens, total saving - 97.3 %
97% reduction in GPU compute hours, reduction in cloud storage requirements, reduction in latency.
Minimal code example to run DeepSeek-OCR-
from transformers import AutoModel, AutoTokenizer
import torch
from pathlib import Path
# Load model and tokenizer
MODEL_NAME = “deepseek-ai/DeepSeek-OCR”
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME, trust_remote_code=True)
model = AutoModel.from_pretrained(MODEL_NAME, trust_remote_code=True, use_safetensors=True)
# Choose device (GPU if available, otherwise CPU)
device = “cuda” if torch.cuda.is_available() else “cpu”
if device == “cuda”:
model = model.eval().cuda().to(torch.bfloat16)
else:
model = model.eval()
# Set input image and output directory
IMAGE_FILE = “sample.jpg” # Replace with your image
OUTPUT_DIR = Path(”outputs_single”)
OUTPUT_DIR.mkdir(parents=True, exist_ok=True)
# Define prompt for OCR conversion
prompt = “<image>n<|grounding|>Convert the document to markdown.”
# Run OCR inference
res = model.infer(
tokenizer,
prompt=prompt,
image_file=str(IMAGE_FILE),
output_path=str(OUTPUT_DIR),
base_size=1024,
image_size=640,
crop_mode=True,
save_results=True,
test_compress=True
)
print(”OCR complete. Check:”, OUTPUT_DIR)
Conclusion
DeepSeek-OCR isn’t a final product, it’s a working hypothesis with evidence, The idea that you can store text as vision and recover it nearly losslessly is genuinely interesting. It opens a new angle on old age problem of context length, maybe the solution isn’t bigger window, but a smaller vision.